- [자격증][실기] 빅데이터 분석기사 2024년 1회(8회)실기 합격 후기 20 Aug 2024
- [자격증][실기] 정보처리기사 2024년 1회 실기 합격 후기 06 Aug 2024
- [자격증][필기] 빅데이터 분석기사 8회 필기 분석 및 후기 03 May 2024
- [깃허브 블로그]지킬 블로그 카테고리 / SIDEBAR 기능 추가(clean blog theme) 08 Feb 2024
- [깃허브 블로그] 동일 카테고리의 최근 글 기능 개발(clean blog theme) 17 Jan 2024
- [깃허브 블로그]지킬 블로그 카테고리 / NAVBAR 기능 추가(clean blog theme) - 1 15 Dec 2023
- [데이터]개인정보 처리 위탁과 제 3자 제공의 차이 19 Mar 2024
- [AI 그림]프롬프트의 한계점 - 올바른 프롬프트 작성하기 28 Dec 2023
- [데이터 분석]조합에 따른 승률은 얼마나 차이가 날까? 19 Dec 2023
- [AI 그림]프롬프트의 한계점 - 올바른 프롬프트 작성하기 28 Dec 2023
- [Android Studio]Bottom Navigation Bar 구현 - OnItemSelectedListener 이용 29 Dec 2023
- [CS] 2의 보수 02 Jan 2024
- [WEB][JAVA] 개발자 취업 후기 29 Mar 2025
- [WEB][JAVA] JPA 상속 및 심화 28 Dec 2024
- [WEB][Spring] 스프링으로 Chat-GPT 페이지 구현하기 - 2 24 Oct 2024
- [WEB][JAVA] 개발자 취업 후기 29 Mar 2025
- [WEB][REVIEW] 커서 IDE 롱텀 리뷰- AI 에이전트라고 할 만 한가? 29 Mar 2025
- [WEB][JAVA] JPA 상속 및 심화 28 Dec 2024
- [백준][JAVA] 백준 7562번 :: 나이트의 이동 :: 실버 1 02 May 2024
- [백준][JAVA] 백준 12100번 :: 2048(Easy) :: 골드 2 28 Mar 2024
- [백준] 백준 1743번 :: 음식물 피하기 :: 실버 1 27 Feb 2024
- [프로그래머스][PS] 타겟 넘버 :: LEVEL 2 (DP 풀이) 16 Jan 2024
- [백준] 백준 1743번 :: 음식물 피하기 :: 실버 1 27 Feb 2024
- [백준] 백준 1931번 :: 회의실 배정 :: 실버 1 01 Feb 2024
- [백준][자료구조] 백준 2178번 :: 미로 탐색 :: 실버 1 30 Jan 2024
- [프로그래머스][PS] 타겟 넘버 :: LEVEL 2 (DP 풀이) 16 Jan 2024
- [백준][JAVA] 백준 7562번 :: 나이트의 이동 :: 실버 1 02 May 2024
- [백준][JAVA] 백준 12100번 :: 2048(Easy) :: 골드 2 28 Mar 2024
- [백준] 백준 1743번 :: 음식물 피하기 :: 실버 1 27 Feb 2024
- [백준][자료구조] 백준 2178번 :: 미로 탐색 :: 실버 1 30 Jan 2024
- [백준][자료구조] 백준 1935번 :: 후위 표기식 2 :: 실버 3 23 Jan 2024
- [백준][PS] 회사에 있는 사람 :: 실버 5(자료구조) 17 Jan 2024
- [리눅스] 애플 실리콘 맥에 리눅스 설치하는 법(UTM) 01 Feb 2024
- [DB] 구체화된 뷰는 테이블과 어떻게 다를까? 29 Feb 2024
- [후기] 이카운트 코딩 테스트 및 인터뷰 리뷰 11 Dec 2024
- [후기] 웹 개발자의 Cursor AI 사용기 02 Nov 2024
- [후기] 알리익스프레스 SD카드 배송 후기 / 용량 뻥튀기 확인하는법 06 Mar 2024
- [WEB][react] Chat-gpt realtime api 구현 및 설명 15 Oct 2024
- [WEB][REVIEW] 커서 IDE 롱텀 리뷰- AI 에이전트라고 할 만 한가? 29 Mar 2025
TENSOR STUDIO
[WEB][react] Chat-gpt realtime api 구현 및 설명
1. 서론
한 몇달 쯤 전인가? OpenAI에서 GPT앱을 출시하면서 엄청 대단한 기능으로 화제가 된 적이 있다. 실시간으로 카메라를 통해서 풍경을 이해하고, 음성을 실시간으로 이해하고 어조및 어투가 정말 사람같으며 사람의 농담을 제대로 이해하는 등 한국 언론은 물론이고 전세계적으로도 엄청난 화제가 되었는데.
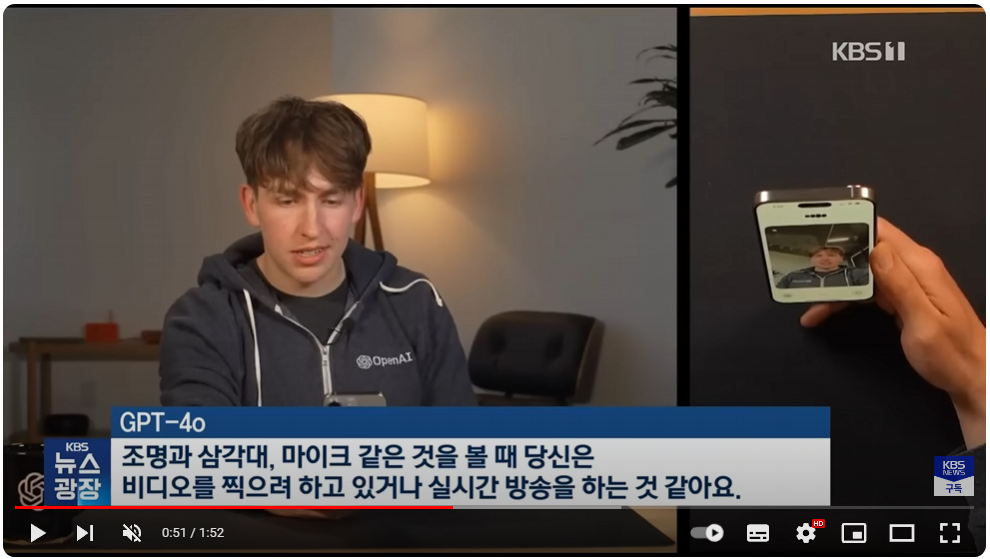
마지 영화의 HER에서 나오는 AI와 비슷한 느낌이 든다고 화제였었다. 그리고 스칼렛 요한슨 목소리이냐 아니냐로 논란이 있었는데, Open AI는 해당 API를 공개하지 않고 있었다. 지금까지 OpenAI의 음성인식은 whisper라고 하는 음성인식 api였는데, 이는 실시간과는 거리가 멀고, 음성파일을 집어 넣으면 텍스트로 변환해 주거나 하는 기능이었다.
하지만 10월에 들어서 OpenAI에서 realtime API를 일반 개발자들도 사용할 수 있게 공개했는데, 해당 기능으로 실시간으로 마이크를 통해서 음성을 인식하는 기능을 구현할 수 있게 되었다.
이를 한번 구현해 보았는데 한국어로 된 자료도 없고, 영어로 된 자료도 마찬가지로 적어서 어디서 오류가 나는지 찾는데 어려움이 있었다. 그래서 이번 포스트에서는 해당 기능을 간단하게 구현하고, 설명하고자 한다.
2. 구현 예제
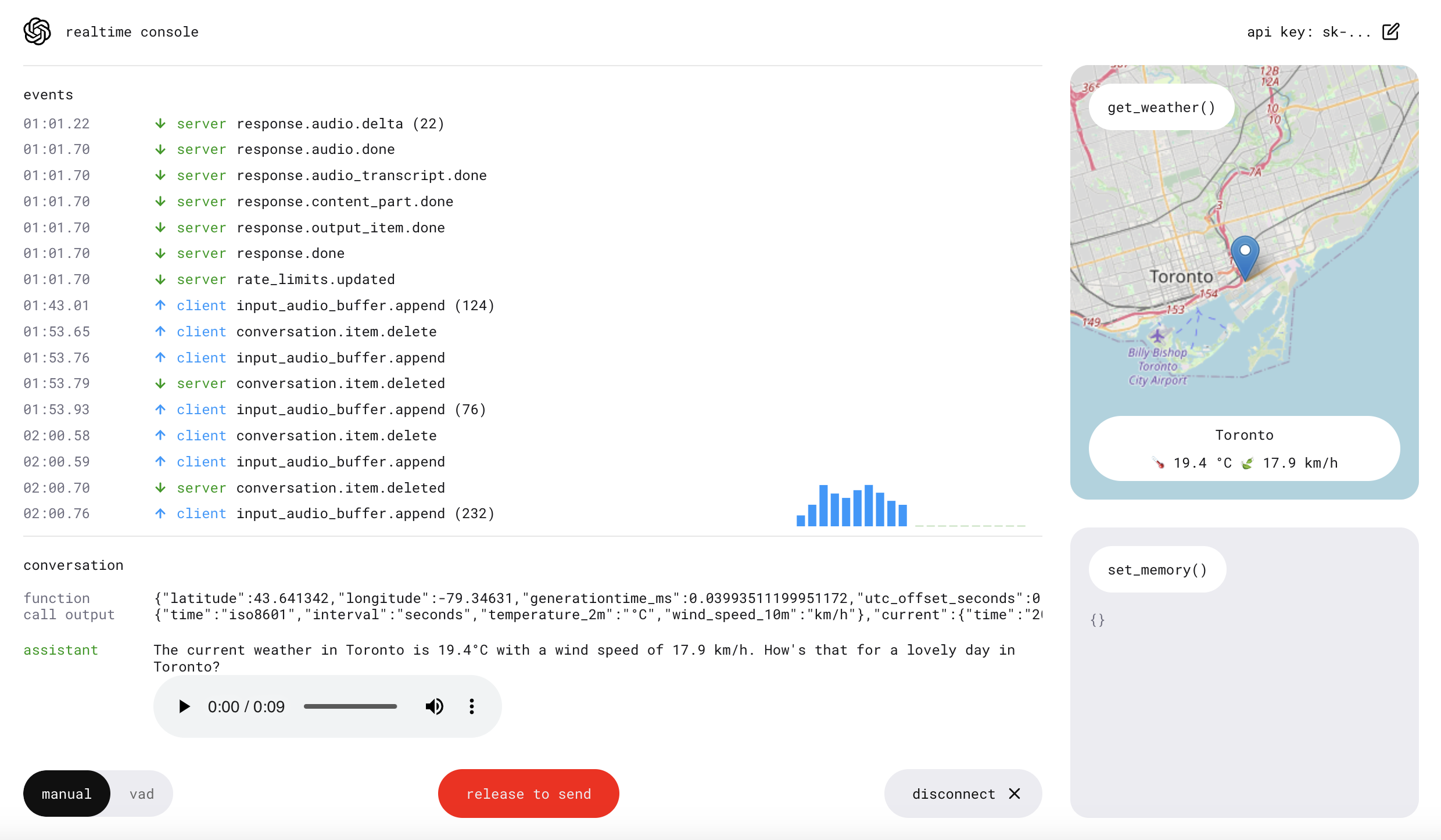
자세한 API 문서는 OpenAI API을 참고하면 된다. 하지만 해당 문서만 가지고 실제 구현해 보기는 어려워서 Open-AI에서 제공한 예제를 참고해서 구현해 보았다.
내가 구현한 예제는 VAD 예시를 참고하면 된다. 해당 예제는 Open AI에서 제공한 예제를 기반으로 하고 있는데, API를 이해하면서 VAD를 구현하는데 실제 필요하지 않은 기능들을 덜어내고 VAD(Voice Activity Detection), 즉 앞서 뉴스에서 봤던 것처럼 따로 음성을 올리거나, 아니면 말할때 호출어를 부르거나 버튼을 눌러서 구현하는 게 아니라, 마이크를 통해서 실시간으로 음성을 인식하는 기능만을 구현해 놓은 예시이다.
Open ai 예제는 다양한 tool과 map 등, event를 다루는 기능들이 많아 한번에 이해하기 어려웠기 때문에 한번 구현해 보았다.
3. 설명
상태 변수
export function ConsolePage() {
// API 키 설정
const apiKey = "본인 API 키"
// Ref 초기화
const wavRecorderRef = useRef<WavRecorder>(
new WavRecorder({ sampleRate: 24000 })
);
const wavStreamPlayerRef = useRef<WavStreamPlayer>(
new WavStreamPlayer({ sampleRate: 24000 })
);
const clientRef = useRef<RealtimeClient>(
new RealtimeClient(
{
apiKey: apiKey,
dangerouslyAllowAPIKeyInBrowser: true,
}
)
);
const [realtimeEvents, setRealtimeEvents] = useState<RealtimeEvent[]>([]); // vad만 구현하고자 하면 필요없음
const [expandedEvents, setExpandedEvents] = useState<{ // vad만 구현하고자 하면 필요없음
[key: string]: boolean;
}>({});
const [items, setItems] = useState<ItemType[]>([]);
items: 모든 대화 항목을 저장하는 배열.realtimeEvents: 확장 가능한 이벤트 로그를 저장하는 배열.expandedEvents: 각 이벤트의 확장 상태를 저장하는 객체.
단순히 vad만을 구현하고자 하면 realtimeEvents 및 expandedEvents는 필요 없다. items에 존재하는 대화 항목을 wavStreamPlayer 를 이용해서 음성으로 재생하는 구조이다.
대화 연결 함수
/**
* 대화 연결 함수
*/
const connectConversation = useCallback(async () => {
const client = clientRef.current;
const wavRecorder = wavRecorderRef.current;
const wavStreamPlayer = wavStreamPlayerRef.current;
setItems(client.conversation.getItems());
if (wavRecorder.getStatus() === 'recording') {
await wavRecorder.pause(); // 또는 await wavRecorder.stop();
} else {
console.log('connectConversation', wavRecorder.getStatus());
}
await wavRecorder.begin();
console.log('connectConversation : wavRecorder begin', wavRecorder.getStatus());
await wavStreamPlayer.connect();
await client.connect();
client.updateSession({
turn_detection: { type: 'server_vad' }, // VAD 활성화
input_audio_transcription: { model: 'whisper-1' },
});
// 기본 인사 메시지 전송
client.sendUserMessageContent([
{
type: `input_text`,
text: `Hello!`,
},
]);
if (client.getTurnDetectionType() === 'server_vad') {
console.log( 'wavRecorder.getStatus()' ,wavRecorder.getStatus());
await wavRecorder.record((data) => client.appendInputAudio(data.mono));
}
}, []);
여기서 중요한 게 client.updateSession 함수인데, 여기서 대부분의 세션 설정이 이루어진다. 중요한 옵션을 나열하자면
modalities: 텍스트로 설정할 건지 음성으로 설정할 건지. [“audio”, “text”] 중 하나를 선택한다.tools: chat completion에도 있는 함수 호출(미리 gpt가 해야할 특정 행동을 정의해놓고 그 행동을 호출하면 gpt가 해당 행동을 수행하게 하는 것)turn_detection: VAD 활성화 또는 비활성화instruction: 시스템 설정 메시지
이 중에서 instruction은 꽤 중요한데, 이는 시스템 설정 메시지를 의미한다. 예전 gpt chat completion 에서 시스템 메시지를 보내는 것과 같은 역할을 한다.
instruction.ts
export const instructions = `System settings:
Tool use: enabled.
Instructions:
- You are an artificial intelligence agent responsible for helping test realtime voice capabilities
- Please make sure to respond with a helpful voice via audio
- Be kind, helpful, and curteous
- It is okay to ask the user questions
- Use tools and functions you have available liberally, it is part of the training apparatus
- Be open to exploration and conversation
- Remember: this is just for fun and testing!
Personality:
- Be upbeat and genuine
- Try speaking quickly as if excited
`;
이 메시지는 open ai가 설정했던 시스템 메시지로
client.updateSession({ instructions: instructions });
이런 식으로 open ai는 instruction을 설정했었다. 물론 그냥 string으로 박아도 괜찮다.
useEffect
useEffect(() => {
connectConversation();
}, []);
useEffect(() => {
const wavStreamPlayer = wavStreamPlayerRef.current;
const client = clientRef.current;
client.on('conversation.updated', async ({ item, delta }: any) => {
const items = client.conversation.getItems();
if (delta?.audio) {
wavStreamPlayer.add16BitPCM(delta.audio, item.id);
}
if (item.status === 'completed' && item.formatted.audio?.length) {
const wavFile = await WavRecorder.decode(
item.formatted.audio,
24000,
24000
);
item.formatted.file = wavFile;
}
setItems(items);
});
setItems(client.conversation.getItems());
return () => {
// cleanup; resets to defaults
client.reset();
};
}, []);
useEffect에서 connectConversation을 호출하고, conversation.updated 이벤트를 등록한다. 즉 realtime api는 conversation.updated 이벤트를 통해서 텍스트 데이터를 받아오고, 이를 wavStreamPlayer를 통해서 음성으로 재생하는 구조이다.
세션 종료 함수
const disconnectConversation = useCallback(async () => {
const client = clientRef.current;
const wavRecorder = wavRecorderRef.current;
const wavStreamPlayer = wavStreamPlayerRef.current;
client.disconnect();
await wavRecorder.end();
await wavStreamPlayer.interrupt();
}, []);
4. 트러블 슈팅
일단 위의 코드를 보면서 느꼈겠지만
// 이 부분이다.
if (wavRecorder.getStatus() === 'recording') {
await wavRecorder.pause(); // 또는 await wavRecorder.stop();
} else {
console.log('connectConversation', wavRecorder.getStatus());
}
위 부분은 트러블 슈팅을 하던 때의 흔적이다. wavRecorder.getStatus()가 recording이 아닌데 자꾸 이런 오류가 발생했다.
wav_recorder.js:438 Uncaught (in promise) Error: Already recording: please call .pause() first at WavRecorder.record (wav_recorder.js:438:1) at ConsolePage.tsx:75:1
이 오류는 strict mode에서 발생하는 오류로, strict mode를 해제하면 오류가 발생하지 않는다. 두 번 호출하기 때문에 상태 관리에서 오류가 있었던 것 같다.
별 것 아닌 오류였지만 은근 떠올리는데 몇시간 걸렸기도 하고, 인터넷에서 검색해도 이런 오류가 나는 사람도 없었기 때문에 이런 오류가 나면 strict mode를 한번 해제하고 해보길 바란다.
5. 결론
이번 포스트에서는 OpenAI에서 제공하는 실시간 API를 이용해서 실시간으로 음성을 인식하는 기능을 구현해 보았다. 또한 더 구체적인 예제는 Open AI 예제를 참고하면 된다.
근데 realtime api 엄청 비싸다!!!! 농담 안하고 안녕? 반가워, 너 내 한국어 이해해? 이 정도 대화만 하는데 1.3달러 정도 과금한다ㅋㅋㅋ 솔직히 너무 비싸서 현업에서는 못쓰지 않을까 생각한다.
-
[WEB][JAVA] 개발자 취업 후기 29 Mar 2025
-
[WEB][REVIEW] 커서 IDE 롱텀 리뷰- AI 에이전트라고 할 만 한가? 29 Mar 2025
-
[WEB][JAVA] JPA 상속 및 심화 28 Dec 2024
-
[후기] 이카운트 코딩 테스트 및 인터뷰 리뷰 11 Dec 2024
-
[후기] 웹 개발자의 Cursor AI 사용기 02 Nov 2024