- [자격증][실기] 빅데이터 분석기사 2024년 1회(8회)실기 합격 후기 20 Aug 2024
- [자격증][실기] 정보처리기사 2024년 1회 실기 합격 후기 06 Aug 2024
- [자격증][필기] 빅데이터 분석기사 8회 필기 분석 및 후기 03 May 2024
- [깃허브 블로그]지킬 블로그 카테고리 / SIDEBAR 기능 추가(clean blog theme) 08 Feb 2024
- [깃허브 블로그] 동일 카테고리의 최근 글 기능 개발(clean blog theme) 17 Jan 2024
- [깃허브 블로그]지킬 블로그 카테고리 / NAVBAR 기능 추가(clean blog theme) - 1 15 Dec 2023
- [데이터]개인정보 처리 위탁과 제 3자 제공의 차이 19 Mar 2024
- [AI 그림]프롬프트의 한계점 - 올바른 프롬프트 작성하기 28 Dec 2023
- [데이터 분석]조합에 따른 승률은 얼마나 차이가 날까? 19 Dec 2023
- [AI 그림]프롬프트의 한계점 - 올바른 프롬프트 작성하기 28 Dec 2023
- [Android Studio]Bottom Navigation Bar 구현 - OnItemSelectedListener 이용 29 Dec 2023
- [CS] 2의 보수 02 Jan 2024
- [WEB][JAVA] 개발자 취업 후기 29 Mar 2025
- [WEB][JAVA] JPA 상속 및 심화 28 Dec 2024
- [WEB][Spring] 스프링으로 Chat-GPT 페이지 구현하기 - 2 24 Oct 2024
- [WEB][JAVA] 개발자 취업 후기 29 Mar 2025
- [WEB][REVIEW] 커서 IDE 롱텀 리뷰- AI 에이전트라고 할 만 한가? 29 Mar 2025
- [WEB][JAVA] JPA 상속 및 심화 28 Dec 2024
- [백준][JAVA] 백준 7562번 :: 나이트의 이동 :: 실버 1 02 May 2024
- [백준][JAVA] 백준 12100번 :: 2048(Easy) :: 골드 2 28 Mar 2024
- [백준] 백준 1743번 :: 음식물 피하기 :: 실버 1 27 Feb 2024
- [프로그래머스][PS] 타겟 넘버 :: LEVEL 2 (DP 풀이) 16 Jan 2024
- [백준] 백준 1743번 :: 음식물 피하기 :: 실버 1 27 Feb 2024
- [백준] 백준 1931번 :: 회의실 배정 :: 실버 1 01 Feb 2024
- [백준][자료구조] 백준 2178번 :: 미로 탐색 :: 실버 1 30 Jan 2024
- [프로그래머스][PS] 타겟 넘버 :: LEVEL 2 (DP 풀이) 16 Jan 2024
- [백준][JAVA] 백준 7562번 :: 나이트의 이동 :: 실버 1 02 May 2024
- [백준][JAVA] 백준 12100번 :: 2048(Easy) :: 골드 2 28 Mar 2024
- [백준] 백준 1743번 :: 음식물 피하기 :: 실버 1 27 Feb 2024
- [백준][자료구조] 백준 2178번 :: 미로 탐색 :: 실버 1 30 Jan 2024
- [백준][자료구조] 백준 1935번 :: 후위 표기식 2 :: 실버 3 23 Jan 2024
- [백준][PS] 회사에 있는 사람 :: 실버 5(자료구조) 17 Jan 2024
- [리눅스] 애플 실리콘 맥에 리눅스 설치하는 법(UTM) 01 Feb 2024
- [DB] 구체화된 뷰는 테이블과 어떻게 다를까? 29 Feb 2024
- [후기] 이카운트 코딩 테스트 및 인터뷰 리뷰 11 Dec 2024
- [후기] 웹 개발자의 Cursor AI 사용기 02 Nov 2024
- [후기] 알리익스프레스 SD카드 배송 후기 / 용량 뻥튀기 확인하는법 06 Mar 2024
- [WEB][react] Chat-gpt realtime api 구현 및 설명 15 Oct 2024
- [WEB][REVIEW] 커서 IDE 롱텀 리뷰- AI 에이전트라고 할 만 한가? 29 Mar 2025
TENSOR STUDIO
[자격증][실기] 빅데이터 분석기사 2024년 1회(8회)실기 합격 후기 및 시험 문제
합격 인증
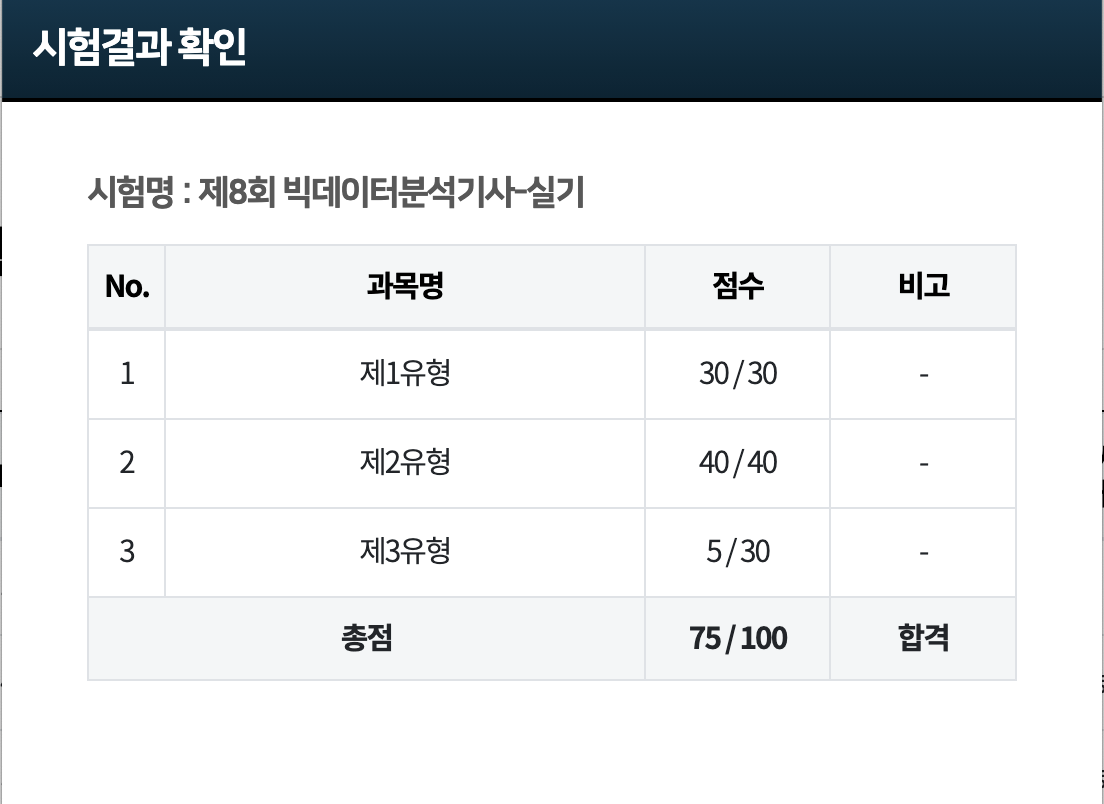
솔직히 좀 부끄럽긴 한데… 3과목 점수가 5점밖에 안나와서 남 보여줄만한 점수는 아니긴 해도, 일단 합격은 합격이니까.
시험 총평
나는 시험을 동부자격검정센터에서 실기 시험을 봤는데 생각보다 시험장이 조금 작긴 했다. 일단 태릉입구 근방 주민은 쉽게 찾아갈 수 있는게, BYC 직영매장 근처에 바로 시험장이 있어서 찾아가기 쉽다.
일단 빅데이터 분석기사의 실기 시험을 공부하며 내가 느꼈던 점은, 필기가 더 어렵고, 실기가 더 쉽다고 느꼈던 점이었다.
1과목

(8회 시험에서는 약 몇백줄 되는 CSV를 제공했는데 다양한 나라의 맥주 판매? 소비 데이터 중에서 특정 조건에 맞는 나라의 정보를 추출하는 문제였다. 즉 꼭 저런 식의 전처리 문제만 나오는 건 아니다..!) 1과목은 데이터 전처리 과목인데, 판다스 라이브러리 등을 사용해서 기초적인 데이터 조작을 할 수 있는지를 묻는 문제인데, 파이썬을 쓸 줄만 안다면 누구나 이 문제를 풀 수 있다. 왜냐하면 help와 dir 명령어를 사용할 수 있기 때문에 pandas를 사용하지 못한다고 하더라도 도움을 받을 수 있기 때문이다. 사실상 30점은 기본으로 가져가는 점수라고 생각한다.
2과목

2과목은 분석 모델링 과목인데, 회귀 모델이나 분류 모델을 사용해서 주어진 문제에 따른 데이터를 반환하는 문제다. 이 문제는 40점 배점으로 이 문제도 어려운 문제는 아니다. 내 기준으로 RMSE가 100에서 120 사이에 있었는데 40점으로 만점을 받았다.
8회차 문제를 설명하자면, 두 지하철역의 주요 변수(이름, 날씨, 기온, 습도, 풍속, 미세먼지 등)를 이용해서 두 지하철역의 승하차 인원을 예측하는 문제였다.
일단 2과목에서 점수를 받지 못하면 합격이 어렵다고 봐야 한다. 2유형은 40점이라 배점이 크기도 하지만, 아예 0점이 나오는 경우가 많아서 숙달될 수 있을 정도로 코드를 써보는 편이 좋다. 내 경험상 2유형을 정리해 보자면 일단 원본 데이터를 잘 살펴 봐야 한다. 예를 들어서, 범주형 변수인 경우에는 라벨 인코딩 보다는(물론 안하는 것보다는 성능이 좋겠지만) pandas의 get_dummies를 이용하는 원핫 인코딩을 사용하는 것이 좋다.
또한, 이번 8회차 시험 문제를 설명했듯이, 두 지하철역의 승하차 인원을 예측하는 문제였는데, 꽤 많은 사람들이 지하철 역 이름을 변수로 사용하지 않아서 점수가 낮게 나왔는데(문제에서는 A역 B역으로 주어졌다) 아마도 A역, B역으로 익명화 되어 있어서 변수로 사용하지 않은 건 이해한다. 하지만 우리가 실제 지하철 역을 이용할 때 항상 집에서 가까운 지하철 역을 이용하는 것처럼, 강남의 유동인구가 많기 때문에 강남역은 당연히 노선도의 끝의 지하철 역보다는 이용자수가 많을 것이 분명하다.
이런 점을 고려하지 않고 지하철 역 이름을 변수로 사용하지 않은 사람들이 많았는데, 물론 사용하지 않다고 하더라도 점수를 받을 수는 있지만 내가 시험장에서 해당 데이터를 기반으로 분석했을때, 해당 변수가 설명력이 가장 높은 변수였기 때문에 아마 점수가 조금 떨어졌을 것이다. 이렇듯 어느정도 실제 데이터를 살펴보는게 중요하다!
그리고 돌아다니는 팁으로 랜덤포레스트 회귀 & 분류를 암기해 가는 2과목 팁이 존재하는데 실제로 이 방법이 가장 좋은 것 같다. 실제 시험장에서 결측치와 이상치 제거를 수행한 뒤에 선형 회귀 및 다양한 모델을 사용해서 예측을 수행했는데, 그냥 원 핫 인코딩을 적용한 랜덤포레스트 회귀가 가장 좋은 성능을 보였다.
그리고 0점 나오는 경우가 많았는데, 이는 csv 파일을 저장하지 않은 경우도 있겠지만 정답 행 갯수보다 적거나 많은 행을 제출해서 그렇다. 이런 경우에는 0점이 나올 수 있기 때문에 주의해야 한다. 앞에 있던 사진처럼 총 행의 갯수(학습용 데이터 수, 평가용 데이터 수)를 제공해주기 때문에 무조건 csv 파일을 제출할 때 정답 행 갯수와 같은지 len() 함수 등을 이용해서 꼭꼭 확인해야 한다!!
3과목

물론 5점 맞은 주제에 무슨 후기냐 싶겠지만, 변명을 하자면 문제가 두문제 나오는데, 각각 5점짜리 소문항 3개씩 15점짜리 문제 두 개였다. 각각 문제는 1번 소문항이 틀리면 나머지 두개의 문항도 모두 틀리는 구조이기 때문에 2번 문항에서 t-검정의 유의구간을 반대로 설정하는 실수를 저질러서 모두 다 틀려버리고 말았다….
개인적으로는 3과목이 가장 어려운 과목이라고 생각하고, 앞으로도 계속 어려워 질 것이라고 생각한다. 그 이유는 일단 지금 3과목에서는 통계적 검정을 주로 물어보기는 하지만 꼭 통계적 검정(t 검정 혹은 카이제곱 검정)을 물어보지 않을 수도 있다는 점이다. 실제로 저 예시 문제에서 나온 것처럼 선형 회귀의 계수나 변수 중요도, 오즈비를 물어보는 경우가 대부분이었다. 실제 기 치뤄진 시험의 기출문제에서도 다른 통계적 지식을 물어보는 경우가 있었는데 이런 경우에는 정말 어려운 문제가 나올 수 있다고 느꼈다. 게다가 빅분기 특성상 기출문제도 정확하지 않기 때문에, 추후에 이 시험의 난이도를 올리고자 한다면 2과목 점수를 낮추고 3과목 점수를 올리는 식으로 변별력을 줄 수도 있지 않을까? 그런 생각이 들었다.

게다가, 지금은 1과목과 2과목을 모두 맞추면 70점으로 무조건 합격이 가능하기에 떠도는 팁으로는 1과목 2과목만 준비해서 특정 방법(랜덤포레스트 회귀 또는 분류) 만 달달 외워서 시험보는 편이 팁이라고 돌아다니는데, 랜덤포레스트 특성상 이런 시험의 데이터 셋에서는 어느정도 무조건적으로 성능이 좋게 나올 수 밖에는 없기 때문에… 시험 점수 등을 조정해서 3과목을 공부할 수 밖에는 없게끔 시험을 언젠가 바꿀 수도 있지 않을까 생각이 들었다.
마치며
빅데이터 분석기사는 일단 필기를 합격했다면 실기는 수월하게 합격할 수 있는 시험이라고 느꼈다. 비록 작업형 시험이기는 하지만 코드가 정말 익숙하지 않은 사람이라도 충분히 합격할 수 있는 시험이다. 일단 수험서로는 ㅇㄱㅈ 출판사의 책을 사용했는데, 솔직히 별로 좋지 않았다고 할 수 밖에는 없다. 내용이 완전 틀린 내용이 실려있기도 했고, 해설과 본문 내용이 충돌되는 경우도 많았다. 다른 출판사의 책을 보지는 않았지만 사는 것이 더 좋지 않을까? 그런 생각은 있다. 적어도 2024년에는..
아무튼, 이렇게 빅데이터 분석기사 24년 1회 후기를 마친다!!
-
[자격증][실기] 빅데이터 분석기사 2024년 1회(8회)실기 합격 후기 20 Aug 2024
-
[자격증][실기] 정보처리기사 2024년 1회 실기 합격 후기 06 Aug 2024
-
[자격증][필기] 빅데이터 분석기사 8회 필기 분석 및 후기 03 May 2024
-
[자격증] 리눅스 마스터 2급 2401회 합격 후기 28 Mar 2024
-
51회차 SQLD 시험 후기 07 Dec 2023